검색 search이란 컴퓨터에 저장한 자료 중에서 원하는 정보를 찾는 작업이다. 다르게 말하자면, 원하는 검색키를 지닌 항목을 찾는 것이며, 원하는 항목이 있을 경우엔 '검색 성공', 없을 경우엔 '검색 실패'가 된다. 원소의 삽입 삭제를 위해서도 검색 연산을 수행하기도 한다.
검색 알고리즘을 고를 땐 고려해야 할 사항이 있다. 수행 시간 복잡도, 자료구조, 정렬 여부, 자료의 위치 등이 있다.
검색 수행 위치에 따라, 메모리에서 수행하면 내부 검색, 보조기억장치에서 수행하면 외부 검색으로 나뉜다.
검색 방식에도 분류가 있다. 검색 대상의 키를 저장된 자료의 키와 비교하여 검색하는 '비교 검색'과 계수적인 성질 값을 이용한 계산으로 검색하는 '계산 검색'이 있다.
순차 검색 Sequential search
선형 검색linear search으로, 배열이나 연결리스트로 정렬된 자료를 처음부터 순서대로 검색하는 방법이다.
장점 : 단순한 알고리즘으로 구현 간단.
단점 : 자료가 많은 경우 검색시간이 오래 걸림. 전부 평균 시간 복잡도는 'O(n)'이다.
- 정렬되지 않은 배열 순차 검색
첫 번째 원소부터 순서대로 원소를 검색한다. 키값이 일치하는 원소라면 그 인덱스를 반환한다.

- 정렬된 배열 순차 검색
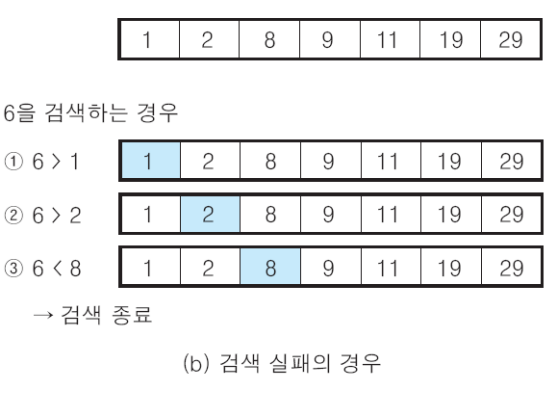
처음부터 순서대로 검색하되 찾는 키값이 원소 값보다 작으면 없는 것으로 간주하고 검색 종료한다.
이진 검색 Binary search
정렬된 배열 원소 중에서 검색 키값을 찾기 위해 일단 가운데 위치한 원소와 비교해보고 다음 대상을 결정하는 방법이다.
검색 키값이 가운데보다 크면 뒷쪽에서 이진 검색하고, 작으면 앞쪽에서 검색한다. 검색 키값을 찾을 떄까지 재귀적으로 이를 반복한다.
이를 적용하기 위해선 자료구조 내 원소들이 정렬되어 있어야 하고, 배열처럼 특정 위치의 원소에 직접 접근이 가능해야 한다.
또한, 원소를 삽입삭제할 경우 배열을 오름차순으로 정렬하기 위한 추가 작업이 필요하다.

퀵정렬과 유사하여 시간 복잡도는 O(log n)이다.
이진 탐색 트리 검색 Binary search tree

이진 탐색 트리는 이전에도 언급했듯, 여기서도 별 차이가 없다.
트리 균형이 맞는다면, 시간 복잡도는 O(log n)이다. 삽입, 삭제도 마찬가지다.
편향 이진 트리일 경우 O(n)이 걸린다.
해싱 Hashing
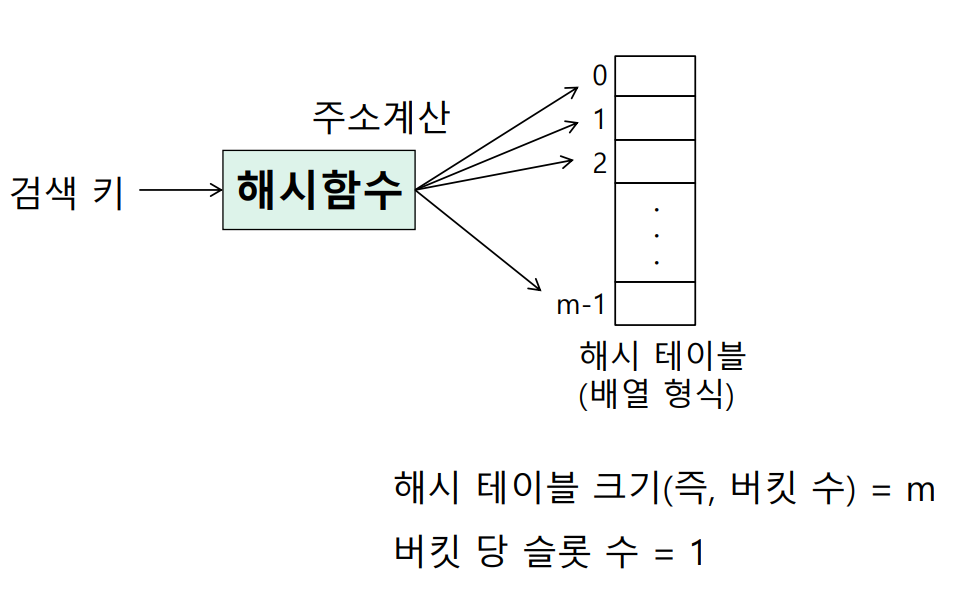
산술적인 연산으로 키가 있는 위치를 계산해서 바로 찾아가는 계산 검색 방식이다. 원소를 저장한 해시 테이블 hash table에서 원소의 키값을 원소의 위치로 변환하는 해시 함수 hash function로 원소를 찾는 방법이다.
해시 함수를 통해 얻는 해시 주소에 해당하는 테이블로 이동 후, 찾는 항목이 있으면 검색 성공, 아니면 실패다.
모든 요건을 다 갖췄다는 가정 하에 검색/삽입/삭제 시간 복잡도는 O(1)이다.
해싱을 구현할 때 다음과 같은 사항을 결정해야 한다.
- 해시 함수
- 해시 테이블 크기
- 충돌 해결 방법
이를 설명하기 앞서 해싱 용어부터 알고 가자.
- 충돌 Collision : 서로 다른 키값에 대해서 해시함수에 따른 주소가 같은 경우
- 해당 버킷이 비어있는 슬롯이면 동의어synonym 관계로 저장한다.
- 버킷이 포화상태면 오버플로우overflow로 저장하지 않는다.
- 동의어, 동거자 synonym : 서로 다른 키값이지만 같은 버킷에 저장된 키 값들.
- 키값 밀도 : 사용 가능한 전체 키 값 중에서 현재 해시 테이블에 저장된 키 값 개수의 비율. 키값밀도 = 사용 중인 키 값 개수/사용가능한 전체 키값 개수
- 적재 밀도 load factor : 해시 테이블에 저장 가능한 개수 중에서 현재 테이블에 저장된 개수의 비율. 적재 밀도가 높으면 해시 테이블 성능이 떨어진다. 다만 테이블 크기를 늘려서 해결할 수 있다. 적재 밀도 = 실제 사용 중인 개수 / 버킷개수*슬롯개수.
해시함수의 조건과 종류
바람직한 해시 함수의 조건은 다음과 같다. 이 두 가지를 유의해야 한다.
- 키값들이 해시 테이블에 고르게 분포할 수 있도록 주소를 계산해야 한다. 즉, 가능한한 충동을 적게 발생시켜야 한다.
- 계산이 쉬워야 한다. 비교검색보다 빨라야 해싱이 의미가 있다.
이제 해시 함수에는 어떤 종류가 있는지 알아보자.
- 비트 추출 bit extraction 방법
해시 테이블 크기가 2^n이라면 키 값에서 n개의 비트를 추출해서 주소로 사용하는 방법이다.
키값의 특정 부분만 고려해서 충돌 발생 가능성이 높다.
- 중간-제곱 mid-square 방법
해시 테이블 크기가 2^n이라면 제곱한 키값에서 n개의 비트를 추출해서 주소로 사용하는 방법이다.
이는 비트 추출보다 충돌 가능성이 덜하다.
- 나누기 division 방법
나머지 연산을 사용하는 방법이다. 즉, h(k) = k mod m 같은 식이다.
m으로 나눈 나머지 값은 0~m-1이므로 테이블의 인덱스로 사용할 수 있다. 물론 충돌이 발생하지 않고 고르게 분포해야 하므로 m을 적당한 크기의 소수prime number로 정해야 한다.
- 곱하기 multiplication 방법
키 값 k와 정해진 실수 a를 곱한 결과에서 소수점 이하 부분만 테이블 크기 m과 곱한 결과를 주소로 사용하는 방법이다.
h(k) = floor[m ∙ (k α mod 1)]
물론 m이 소수prime number일 필요는 없다.
해싱 충돌 처리 방법
버킷 당 슬롯이 하나라 가정하면 충돌, 즉 오버플로우가 생긴다. 이를 해결하기 위한 방법은 아래와 같다.
- 선형 개방 주소법 linear open addressing
해시 함수로 계산한 주소에 이미 값이 있다면 다음 버킷을 조사하고, 여기도 차있으면 다음 버킷을 조사한 다음, 비어 있다면 키 값을 저장한다. 이 과정을 반복해서 비어있는 버킷을 찾아낸다. 마지막 버킷에 도달했으면 다음 버킷은 첫 번째 버킷이 된다.

- 체이닝 chaining
하나의 버킷에 여러 키 값을 저장할 수 있도록 각 버킷을 연결리스트로 구현하는 것이다.
저장할 때, 해시 함수로 버킷 번호를 얻고 그 버킷에 키 값이 존재하지 않으면 삽입하고, 있다면 저장 실패한다.

'기록 > 알고리즘' 카테고리의 다른 글
| 알고리즘(2) - 알고리즘 설계와 기초 분석 (1) | 2023.03.08 |
|---|---|
| 알고리즘(1) - 알고리즘이란 (0) | 2023.03.08 |
| 정렬 알고리즘 (0) | 2022.12.02 |
| 자료구조(7) - 그래프 Graph (0) | 2022.11.25 |
| 자료구조(6) - 이진 탐색 트리, 최대힙 (0) | 2022.11.10 |