원시적인 naive 매칭
문자열 하나하나에 패턴문자열을 대조해보는 방법으로, O(mn)의 수행시간을 갖는다. 다만 이전에 비교했던 불일치 건에 대한 사실을 전혀 활용하지 못하기에 비효율적이다.
Rabin-Karp 알고리즘
문자열 패턴을 수치화하여 문자열 비교를 수치비교로 대신한다.
수치화 방법은 다음과 같다. 가능한 문자 집합의 크기에 따라 진수가 결정된다.
만약 A = {a,b,c,d,e}이면, |A| = 5이다. 여기서 문자열 ad를 수치화한다고 했을 때 수치는 다음과 같다.
0*5^1 + 3*5^0 = 4 (4가 문자열 ad의 수치화, 맨앞의 숫자는 알파벳의 순서)
문자열 수치화로 문자열 매칭을 수행하려면 다음과 같은 문제점을 해결해야 한다.
- 수치화 작업의 부담
- 보통 하나의 문자열들을 일일이 계산하는 경우, 전체 텍스트 문자열과 비교할 때 Θ(mn)이 소요된다. 이는 즉슨, 원시적인 매칭에 비해 나은 것이 없다는 의미가 된다.
- 수치가 지나치게 커져 오버플로우가 발생
- 수치가 커짐에 따라 컴퓨터 레지스터용량 초과, 즉 오버플로우로 이어진다. 나머지 연산 모듈러를 사용하여 수치를 제한하면 된다. 여기서 mod q에서 q를 충분히 큰 소수로 정하되 레지스터에 수용될 수 있는 크기여야 한다.
문제점을 해결하면 평균적으로 수행시간은 Θ(n)이 걸린다.
다만, 모든 문자열과 패턴문자열이 동일한 최악의 경우 Θ(mn)의 시간이 걸린다.
KMP 알고리즘
오토마타를 이용한 매칭과 동기가 유사하다. 이 말인 즉슨, 매칭에 실패했을 대 돌아갈 상태를 준비해둔다는 의미다. 오토마타를 이용한 매칭보다 전처리가 단순해진다.

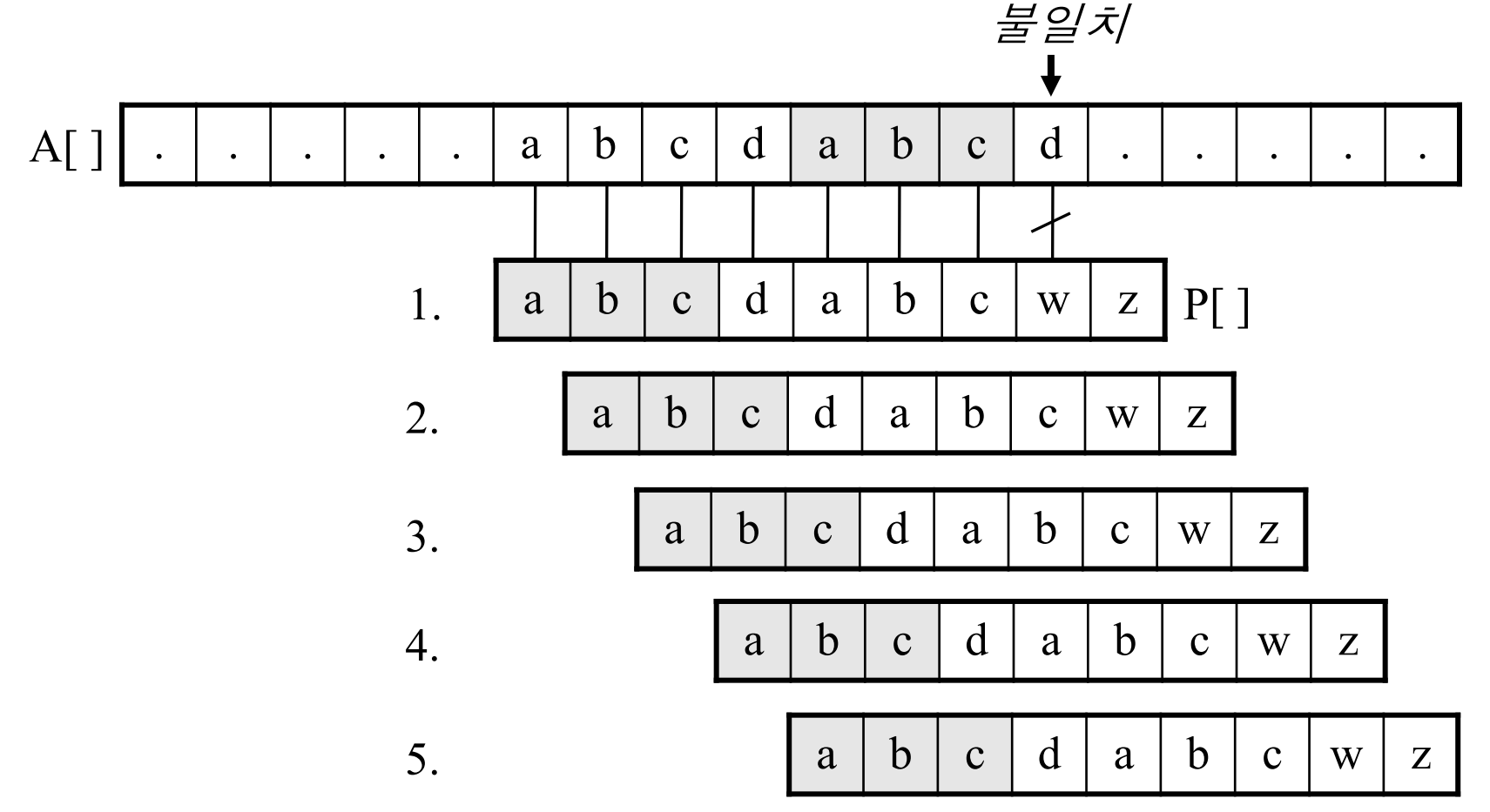
위의 그림을 보자. abcdabc까지는 매칭되나 w에서 실패하였다. 맨 앞의 abc와 실패직전의 abc는 동일하다.

수행시간은 평균 Θ(n)이다. 전처리 작업 알고리즘에서는 Θ(m)이다.
Boyer-Moore-Horspool 알고리즘
앞서 언급한 알고리즘들은 텍스트 문자열을 적어도 한 번씩은 훑어본다는 것이다. 보이어 무어 알고리즘은 굳이 텍스트 문자열을 다 보지 않아된다는 발상의 전환이다. 패턴의 오른쪽부터 비교하여 불일치하면 매치가능성이 없기에 점프한다는 의미다.
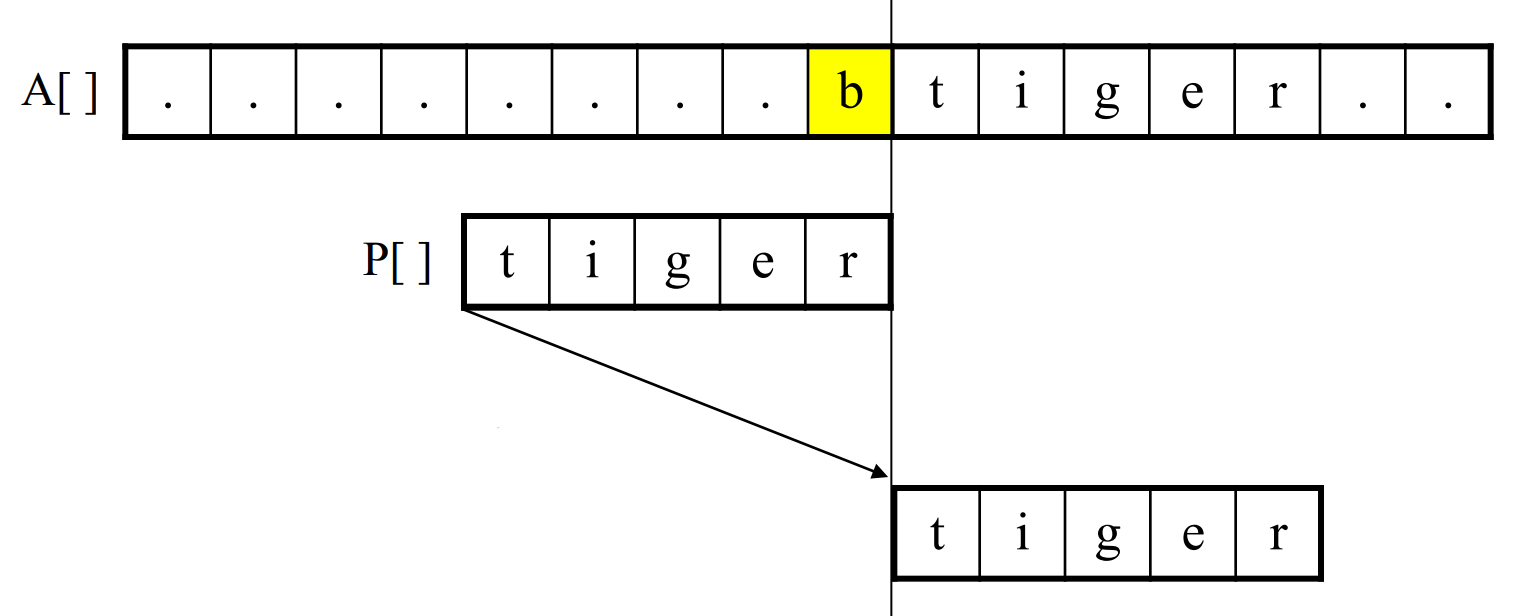
패턴 문자열 P[]를 보자. 맨끝에서 비교하는 문자는 b이며 패턴문자열에는 b가 없다. 따라서 패턴 전체가 이를 뛰어넘어도 된다.
보이어 무어 알고리즘에서는 전처리를 위해 점프에 대한 정보를 저장해둔다.

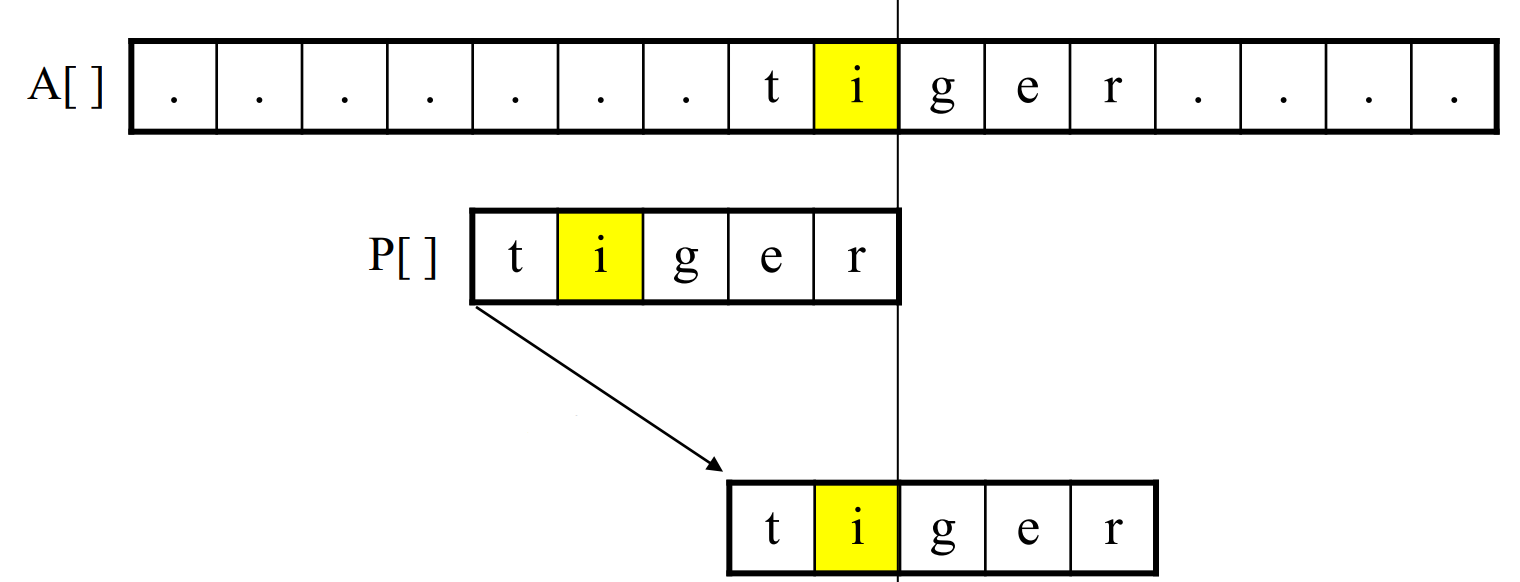
아래 정보를 토대로 위의 점프정보에 불일치 시 넘어야 할 단계를 저장한다. i는 r의 세 번째 왼쪽 칸에 있으므로 한 번에 3칸을 건너뛰어도 된다.
패턴 문자열 중 같은 값이 여러 개이면 그 값 중 작은 것을 고른다.
평균적으로 Θ(m) (패턴 길이),
최악의 경우 Θ(mn) (패턴길이*문자열길이),
최선의 경우 Θ(n/m) (패턴길이 / 문자열길이)
'기록 > 알고리즘' 카테고리의 다른 글
| 알고리즘 - DFS와 BFS (1) | 2024.10.22 |
|---|---|
| 알고리즘(17) - NP-완비 (0) | 2023.06.09 |
| 알고리즘(15) - 그리디 알고리즘 greedy algorithm (0) | 2023.06.07 |
| 알고리즘(14) - 그래프 (0) | 2023.05.24 |
| 알고리즘(13) - 동적 프로그래밍 dynamic programming (0) | 2023.05.17 |