고급 정렬
고급 정렬들은 평균 수행시간이 Θ(nlogn)이다. 이 중에 퀵 정렬이 가장 많이 사용된다.
병합 정렬 merge sort
정렬할 대상을 반으로 나누고, 반으로 나눈 전반부와 후반부를 독립적으로 정렬한다. 정렬된 두 부분을 합치면서 정렬된 배열을 얻는다.
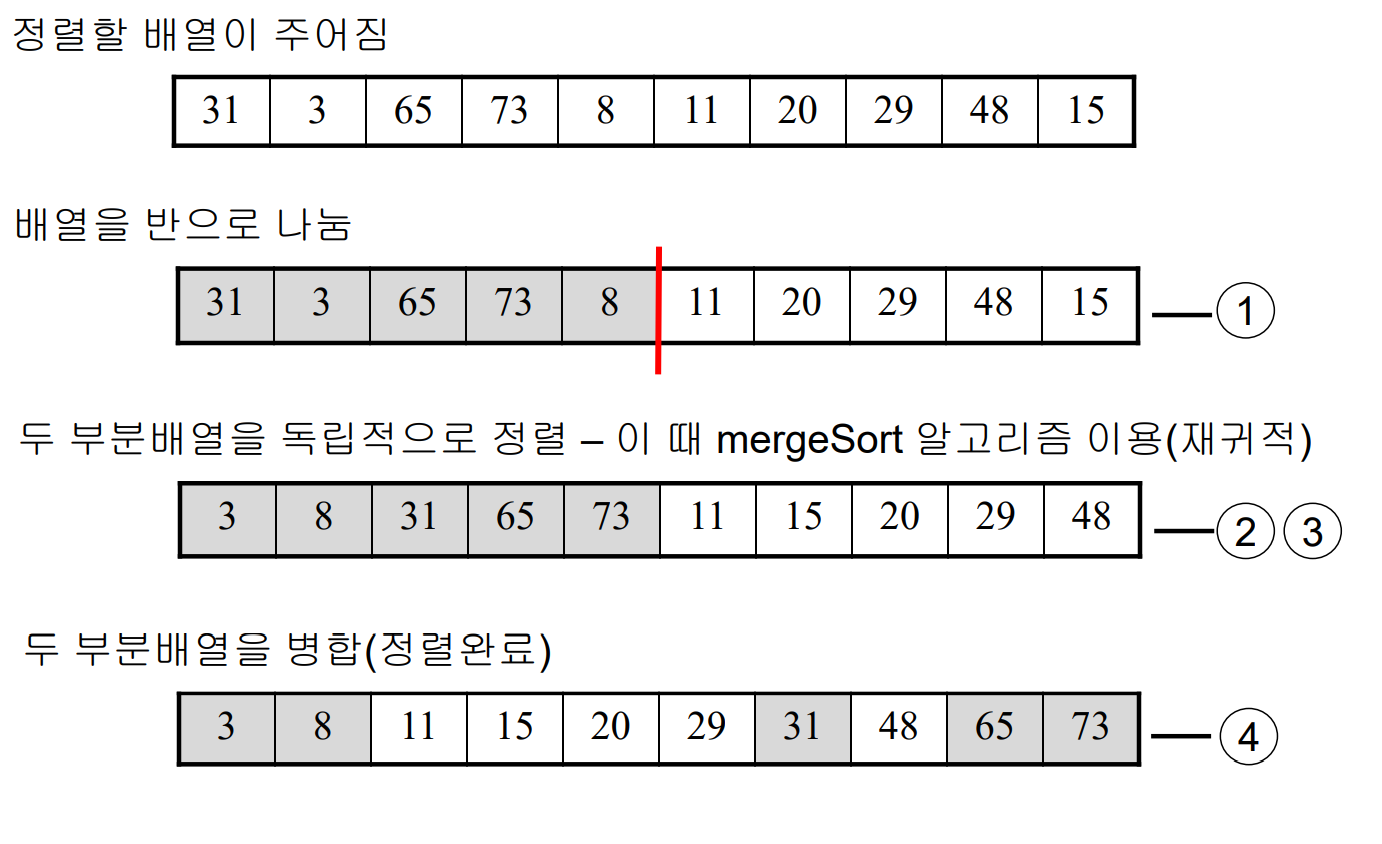
병합정렬 또한 재귀알고리즘이다. 수행시간은 두 부분을 각각 정렬하는 시간과 병합시간을 합하면 된다. 점화식으로 표현하면 다음과 같다.
T(n) = 2T(n /2) + Θ(n)
마스터정리를 이용한 점근적 표기로는,
a=2, b=2
f(n)=n
h(n)=nlog2 =n
따라서, h(n)이 더 크므로 T(n)=Θ(nlogn)
병합 정렬을 자바 코드로 구현해보자.
public class MergeSort {
public static void sort(int[] arr) {
int n = arr.length;
if (n < 2) {
return;
}
int mid = n / 2;
int[] leftArr = new int[mid];
int[] rightArr = new int[n - mid];
for (int i = 0; i < mid; i++) {
leftArr[i] = arr[i];
}
for (int i = mid; i < n; i++) {
rightArr[i - mid] = arr[i];
}
sort(leftArr);
sort(rightArr);
merge(leftArr, rightArr, arr);
}
private static void merge(int[] leftArr, int[] rightArr, int[] arr) {
int i = 0, j = 0, k = 0;
int leftSize = leftArr.length;
int rightSize = rightArr.length;
while (i < leftSize && j < rightSize) {
if (leftArr[i] <= rightArr[j]) {
arr[k] = leftArr[i];
i++;
} else {
arr[k] = rightArr[j];
j++;
}
k++;
}
while (i < leftSize) {
arr[k] = leftArr[i];
i++;
k++;
}
while (j < rightSize) {
arr[k] = rightArr[j];
j++;
k++;
}
}
public static void main(String[] args) {
int[] arr = { 4, 2, 6, 8, 5, 1, 7, 3 };
System.out.println("Before sorting: " + Arrays.toString(arr));
sort(arr);
System.out.println("After sorting: " + Arrays.toString(arr));
}
}
퀵 정렬 quick sort
정렬할 배열에서 기준이 될 원소를 하나 고르고, 이를 중심으로, 더 작은 원소는 왼쪽, 나머지는 오른쪽으로 재배치해서 분할한다. 그리고 이 분할된 배열을 각각 독립적으로 정렬한다.

이해를 돕고자 다음을 보자.

partition 메소드는 기준값을 중심으로 작거나 큰 원소값을 재배치한다.
퀵 정렬은 병합 정렬과 마찬가지로 평균 수행시간은 Θ(nlogn)이다. 기준값에 따른 두 부분배열이 밸런스가 좋은 평균과 최선의 경우 모두 이런 수행시간을 갖지만, 매번 기준값이 제일 큰 최악의 경우에는 Θ(n2)이다.
public class QuickSort {
public static void sort(int[] arr) {
quickSort(arr, 0, arr.length - 1);
}
private static void quickSort(int[] arr, int left, int right) {
if (left >= right) {
return;
}
int pivotIndex = partition(arr, left, right);
quickSort(arr, left, pivotIndex - 1);
quickSort(arr, pivotIndex + 1, right);
}
private static int partition(int[] arr, int left, int right) {
int pivotValue = arr[right];
int i = left - 1;
for (int j = left; j < right; j++) {
if (arr[j] <= pivotValue) {
i++;
swap(arr, i, j);
}
}
swap(arr, i + 1, right);
return i + 1;
}
private static void swap(int[] arr, int i, int j) {
int temp = arr[i];
arr[i] = arr[j];
arr[j] = temp;
}
public static void main(String[] args) {
int[] arr = { 4, 2, 6, 8, 5, 1, 7, 3 };
System.out.println("Before sorting: " + Arrays.toString(arr));
sort(arr);
System.out.println("After sorting: " + Arrays.toString(arr));
}
}힙 정렬 heap sort
heap이 되기 위해서는 완전이진트리(complete binary tree)로서 다음 성질을 만족해야 한다. 최소 힙이라면 각 노드의 값이 자식 노드 보다 작거나 같아야 한다. 최대 힙은 자식 노드 보다 크거나 같아야 한다.
힙 정렬은 주어진 배열을 힙으로 만들고, 하나씩 힙에서 제거해서 정렬한다.



구성된 최대힙에서 루트값을 하나씩 제거하면서 정렬한다. 최대 루트값이 빠지면 리프노드 중에서 마지막 노드를 최대값 자리에 배치하고 자식노드들과 값을 비교하면서 제자리를 찾아가게 한다. 아래는 힙정렬의 과정이다.
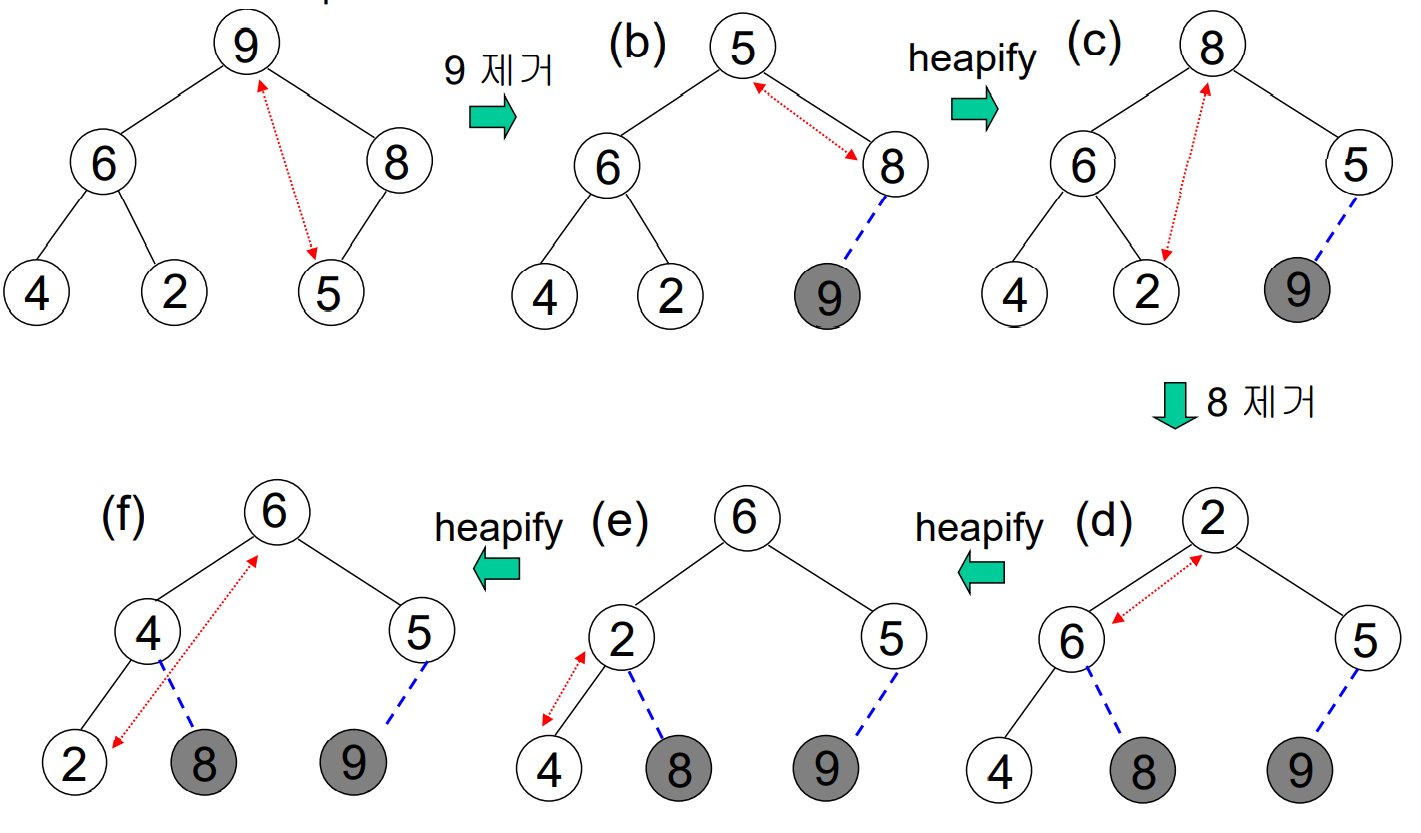
힙은 원소의 삽입과 삭제, 모두 O(log n)의 시간이 걸린다. 힙 정렬일 때는 O(n log n)이지만 실제로는 퀵 정렬을 잘 구현하는 것이 더 빠르다.
'기록 > 알고리즘' 카테고리의 다른 글
| 알고리즘(7) - 선택 알고리즘 Selection algorithm (0) | 2023.03.29 |
|---|---|
| 알고리즘(6) - 특수 정렬(계수 정렬, 기수 정렬) (0) | 2023.03.23 |
| 알고리즘(4) - 정렬 (기본적인 정렬) (0) | 2023.03.14 |
| 알고리즘(3) - 점화식과 점근적 분석 (1) | 2023.03.10 |
| 알고리즘(2) - 알고리즘 설계와 기초 분석 (1) | 2023.03.08 |