검색트리
데이터의 저장과 검색은 자료구조와 알고리즘 분야에서 매우 중요하다. 수행시간에서 커다란 차이를 보이기 때문이다. 데이터의 저장과 검색을 효율적으로 하기 위해서는 적절한 자료구조 및 알고리즘의 사용을 필요로 한다는 사실은 자명하다.
만약 데이터가 들어오는 순서대로 배열에 저장한다고 가정해보자. 자료수가 n개일 때 수행시간은 다음과 같다.
- 새로운 자료 하나를 저장하는 시간은 Θ(1)
- 자료를 검색하는 시간은 Θ(n)
보다시피 검색에는 비효율적이다.
허나, 트리 모양 구조의 검색 트리에 저장한다면 어떨까?
- 저장과 검색, 둘 모두 Θ(log n)의 시간이 걸린다.
검색트리는 자식노드 갯수에 따라, 저장장소에 따라, 검색키에 포함된 필드수에 따라 분류된다. 다만 여기서는 언급하지 않겠다.
이진 검색트리
이진트리는 이전에 다뤘었다. 이진트리의 각 노드는 하나 키 값만을 가지며 키값은 모두 다르다. 최상위 레벨에 루트 노드가 있으며 존재하는 각 노드는 모두 최대 2개의 자식 노드를 가질 수 있다. 그리고 각 노드는 왼쪽 노드의 키값보다 크고, 오른쪽 노드의 키값보다 작다.
이진검색트리 순회
순회는 트리의 노드들을 중순위로 순회해서 키값을 출력한다. 키값을 오름차순으로 순회하는 효과를 낸다.
treeInorderTraverse(t)
{
if (t ≠ NIL) then {
treeInorderTraverse(t.left);
print t.key;
treeInorderTraverse(t.right);
}
}
다음과 같은 이진검색트리가 있다고 해보자.
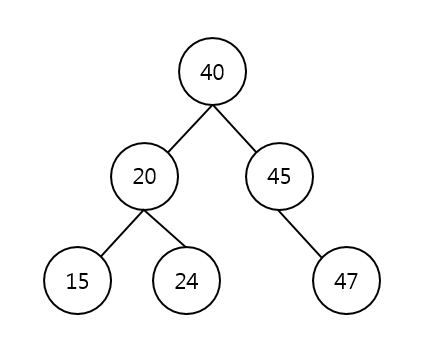
그렇다면 중순위로 순회를 시작하면 순서의 값은 다음과 같다.
20, 15, 24, 40, 45, 47
이진검색트리 검색
검색에 성공하면 해당 노드를 리턴하고, 없다면 null을 리턴한다. 검색 자체는 재귀 알고리즘뿐만 아니라 반복문으로 구현해도 된다.
treeSearch(t, x) // 재귀 알고리즘
{
if (t=NIL or t.key=x) then
return t;
if (x < t.key) then
return treeSearch(t.left, x);
else
return treeSearch(t.right, x);
}
이진검색트리 삽입
삽입도 절차상 검색과 거의 같다. 재귀 알고리즘뿐만 반복문 구현도 가능한다.
treeInsert(t, x) // 재귀 알고리즘
{
if (t = NIL) then {
r.key ← x; ▷ r : 새로 할당받은 노드
return r;
}
if (x < t.key) then {
t.left ← treeInsert(t.left, x);
return t;
}
else { ▷ x > t.key
t.right ← treeInsert(t.right, x);
return t;
}
}
이진검색트리 삭제
가장 손이 많이 가는 부분이다. 트리의 루트 노드와 삭제하고자 하는 노드를 파라미터로 받고, 세 가지 경우에 따라 각각의 처리방법을 실행한다.
– Case 1 : r이 리프 노드인 경우
– Case 2 : r의 자식 노드가 하나인 경우
– Case 3 : r의 자식 노드가 두 개인 경우
Sketch-TreeDelete(t, r) // 삭제 알고리즘의 간단한 골격
{
if (r이 리프 노드) then ▷ Case 1
그냥 r을 버린다;
else if (r의 자식이 하나만 있음) then ▷ Case 2
r의 부모가 r의 자식을 직접 가리키도록 한다;
else ▷ Case 3
r의 오른쪽 서브트리의 최소원소 노드 s를 삭제하고,
s를 r 자리에 놓는다;
}
삭제 알고리즘을 더 자세히 구현하면 다음과 같다.
root: 트리의 루트 노드
r: 삭제하고자 하는 노드
p: r의 부모 노드 (삭제하고자 하는 노드 r이 루트노드인 경우 제외)
treeDelete(r, p) ▷p의 자식 r을 삭제
{
if (root = r) then ▷ r이 루트 노드
root ← deleteNode(r);
else if (r = p.left) then ▷ r이 p의 왼쪽 자식
p.left ← deleteNode(r);
else ▷ r이 p의 오른쪽 자식
p.right ← deleteNode(r);
}
deleteNode(r) ▷ r을 삭제하고 r 대신 r의 부모에 연결할 노드를 리턴
{
if (r.left = r.right = NIL) then return NIL; ▷ Case 1
else if (r.left = NIL and r.right ≠ NIL) then return r.right; ▷ Case 2-1
else if (r.left ≠ NIL and r.right = NIL) then return r.left; ▷ Case 2-2
else { ▷ Case 3
s ← r.right;
while (s.left ≠ NIL) { ▷ r의 right subtree 중에서 최소인 s 찾음
parent ← s;
s ← s.left;
}
▷ s의 내용을 r에 복사한 후, s를 삭제
r.key ← s.key;
if (s = r.right) then r.right ← s.right;
else parent.left ← s.right;
return r;
}
}
이진검색트리는 평균적으로 Θ(n)의 시간이 걸린다. 그러나, 노드 수 n, 높이 h인 이진검색트리에서 검색, 삽입, 삭제 연산의 수행시간은 O(h)이다. 이는 균형이 많이 깨진 경우를 의미한다. 이는 다시 말하면, 균형 잡힌 이진검색트리를 활용하면 평균 O(log n)의 수행시간을 가질 수 있다.
'기록 > 알고리즘' 카테고리의 다른 글
| 알고리즘(10) - 검색트리 - B-Tree, 다차원 검색트리(KD-Tree) (0) | 2023.04.06 |
|---|---|
| 알고리즘(9) - 검색트리 - 레드블랙트리 red-black tree (0) | 2023.04.04 |
| 알고리즘(7) - 선택 알고리즘 Selection algorithm (0) | 2023.03.29 |
| 알고리즘(6) - 특수 정렬(계수 정렬, 기수 정렬) (0) | 2023.03.23 |
| 알고리즘(5) - 정렬(고급 정렬) (0) | 2023.03.22 |