탐색
인공지능 시스템이 문제해결을 위해서 흔히 사용하는 기법이다. 만약 문재해결을 위해서 취해야 할 행동들이 무엇인지 알고 있지만 어떤 순서로 행동을 취해야 문제가 해결되는지 알지 못하면 가능한 모든 순서 조합을 다 시도해 보아야 한다.
탐색
탐색 방법에는 두 종류가 있다.
- 무 정보 탐색 : 모든 길(조합)을 다 찾아보는 방법
- 휴리스틱 탐색 : 가능성이 높은 곳만을 선별하여 찾아보는 방법
무 정보 탐색
무 정보 탐색 기법은 탐색공간(어떤 문제 공간에서 만들어질 수 있는 모든 상태들의 집합)에 대한 아무런 정보 없이 순서만 정해놓고 탐색을 수행한다.
무 정보 탐색에서 다시 2종류로 나뉘는데 깊이 우선 탐색(DFS)과 너비 우선 탐색(BFS)이다.
- 깊이우선탐색 depth first search
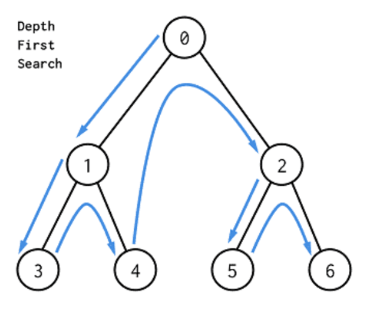
하나의 트리 루트노드에서 리프노드까지 탐색해보고 찾고자 하는 값이 없다면 리프노드의 형제 노드로 넘어가 탐색한다. 이후에도 없다면 루트 노드의 다른 자식 노드까지 탐색하는 방법이다.
시작노드에서 목적노드까지의 가장 짧은 거리를 처음에 찾는 것을 보장할 수 없다. 게다가 하나의 길이 찾아진 후 더 짧은 길이 발견될 수 있다. 이 단점을 보완하려면 깊이를 제한하는 탐색과정을 밟아야 하는데, 상상할 수 있다시피 깊이제한 값이 크면 그것은 너비 우선 탐색이 된다.
- 너비우선탐색 breadth first search

루트노드에서 가장 가까운 자식노드들을 먼저 살펴보고, 없다면 그 자식 노드들을 탐색하는 방법이다.
너비우 탐색에서는 깊이우선탐색의 단점인 더 짧은 거리를 바로 찾을 수 없다는 점을 해결할 수 있다.
휴리스틱 탐색
휴리스틱은 경험으로 해석될 수 있다. 이는 탐색공간에 관한 정보를 탐색에 활용하여 탐색공간을 줄이거나 답으로 사용 가능한 근사치를 빨리 찾을 수 있도록 하는 유용한 정보다.
휴리스틱 탐색은 모호성 때문에 문제의 해가 정확히 존재하지 않을 때 혹은, 주어진 시간 내에 모든 탐색공간을 다 방문할 수 없을 때 유용하다.
휴리스틱 탐색에도 여러 종류가 있다.
- 언덕등반 탐색
모든 도시를 한 번만 방문하는 경로를 짜야 하는 방문상인 문제(traveling salesman problem)가 있다. 도시 수가 n개라면 서로 다른 경로가 (n-1)!/2가지 정도 존재한다. 모든 경우의 수를 정해진 시간에 다 계산해보는 것은 불가능하다. 따라서 여기서 휴리스틱 탐색이 필요하다.
언덕등반 탐색은 평가함수 값에 기반해 경로를 정하는 것이다. 현재 상태의 시작노드(루트노드)에서 자식노드의 평가함수값을 구한다. 자식노드 중 하나의 평가함수 값이 현재 상태의 노드보다 좋다면 그 자식노드를 현재상태 노드로 만든다. 이를 반복하면서 최적의 경로를 찾는다.
결국 언덕등반탐색은 다음 노드를 선택할 때 자식 노드중 목적노드로 인도할 가능성이 가장 높은 노드를 선택하는 방법이다.
- 최고우선 탐색
우선순위큐를 사용하여 언덕등반 탐색에서 생길 수 있는 지역최고에 빠지지 않고 탐색을 수행할 수 있게 하는 것이다. 여기서 우선순위큐란 큐내 요소 중 우선순위가 가장 높은 것이 큐의 가장 앞에 놓이는 큐이다.
언덕등반탐색은 탐색공간을 축소할 수 있지만 최선의 답을 보장하진 못한다. 한 번 길을 잘못들면 더 좋은 상태로 돌아갈 수 없기 때문이다. 따라서 이를 보완하기 위해 선택되지 않은 노드도 다시 탐색의 대상이 될 필요가 있다. 이를 개선하기 위한 것이 최고우선탐색이다.
- A* 알고리즘
어떤 문제는 목적노드까지 어떻게 하면 빨리 찾아갈 수 있는지를 중점으로 보는 게 아니라 시작노드에서 목적노드까지 '최단경로'를 찾아야 하는 경우가 있다. 이때 현재노드에서 목적노드까지 가는 거리가 같다면 시작노드에 현재노드까지의 거리가 짧은 쪽이 전체적으로 이동거리가 짧다. 그렇기에 최단거리 탐색을 위해 평가함수에서 두 가지를 고려해야 한다.
- 시작노드에서 현재노드까지 온 최단거리 => g(n)으로 표시함.
- 현재노드에서 목적노드까지의 최단거리 => h(n)으로 표시함.
따라서 평가함수는 f(n) = g(n)+h(n)이 된다.
여기서 알아둬야 할 것이 있다. g(n)은 지나온 거리이기에 바로 구할 수 있다. 하지만 h(n)은 정확히 알지 못하는 거리다. 그렇기에 추정치를 사용해야 한다. h(n)의 추정치를 h*(n)로 표시하면 f(n)은 f*(n)으로 바뀐다.
- 알파베타 절단 기법 alpha-beta pruning
상태공간 중에 탐색을 고려하지 않아도 최종결과에는 영향을 미치지 않는 노드들을 절단하여 탐색공간을 줄이는 기법이다. max노드가 절대된 경우를 알파절단이라 하고, min노드가 절단된 경우 베타절단이라고 한다.
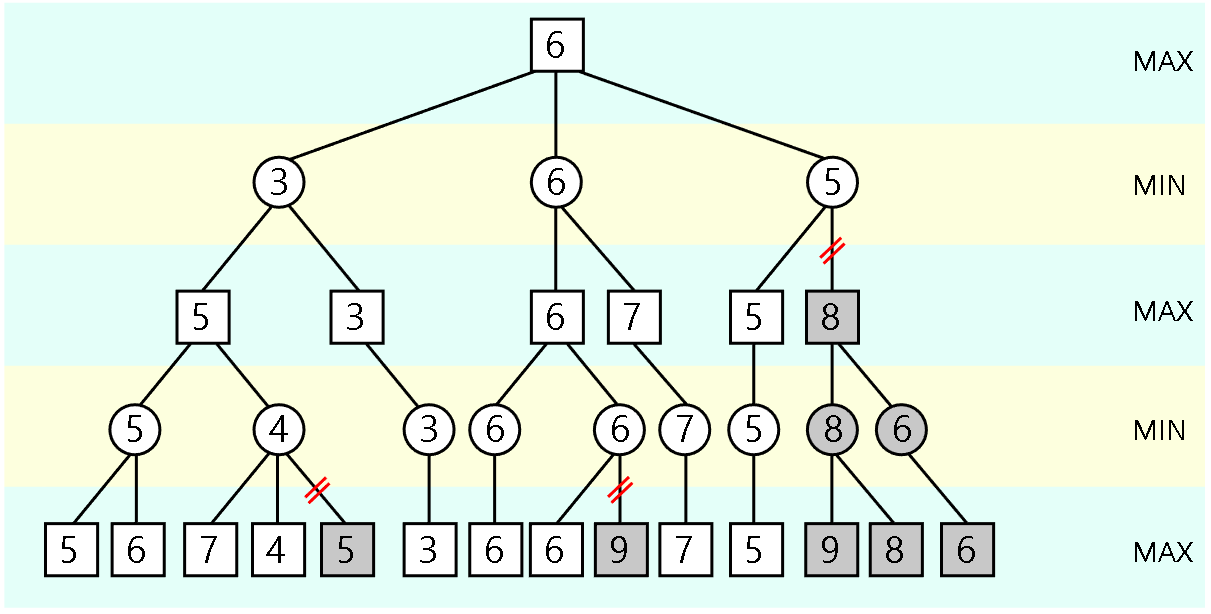
위는 알파베타 절단의 예이다.
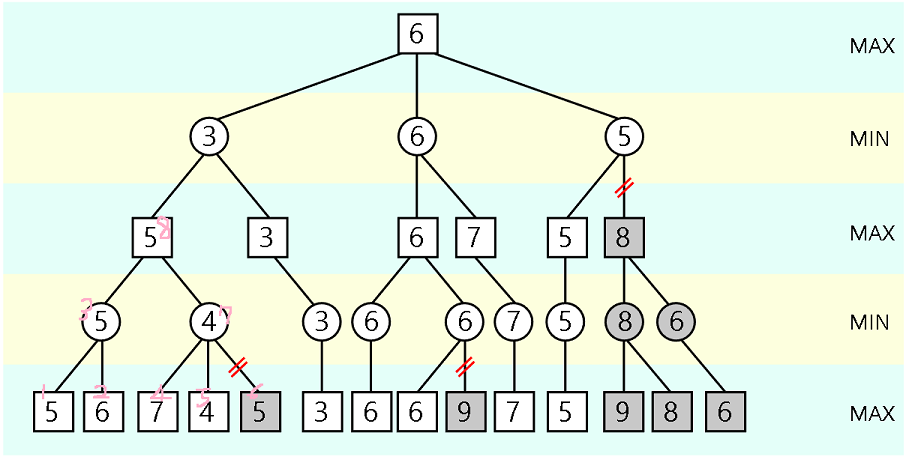
분홍색 번호는 각 노드의 임의의 명칭이다. 왜 6번노드가 절단됐는지 알아보자.
1,2번 노드를 탐색 및 비교하고 min층(가장 작은 수가 올라올 층)으로 1번 노드를 보낸다. 1번 노드 < 2번노드이기 때문이다. 그 이후 4, 5번 노드를 본다. 5번 노드에서 이미 가장 작은 수가 나왔다. 6번 노드는 볼 필요가 없다. 따라서 5번 노드가 7번으로 올라가고 3, 7번 노드는 서로 또 비교한다. max레벨인 8번 노드로 올라가는 것은 3번 노드다.
이러한 과정을 다른 노드에서도 반복하여 최종적으로 결과에 아무런 영향이 없는 노드를 절단하면 된다.
'기록 > 인공지능' 카테고리의 다른 글
| 인공지능(6) - 기계학습과 유전 알고리즘 (0) | 2023.05.03 |
|---|---|
| 인공지능(5) - 퍼지논리 (0) | 2023.05.02 |
| 인공지능(4) - 논리 (0) | 2023.05.01 |
| 인공지능(2) - 지식 표현 (0) | 2023.04.08 |
| 인공지능(1) - 인공지능에 관하여 (1) | 2023.04.07 |