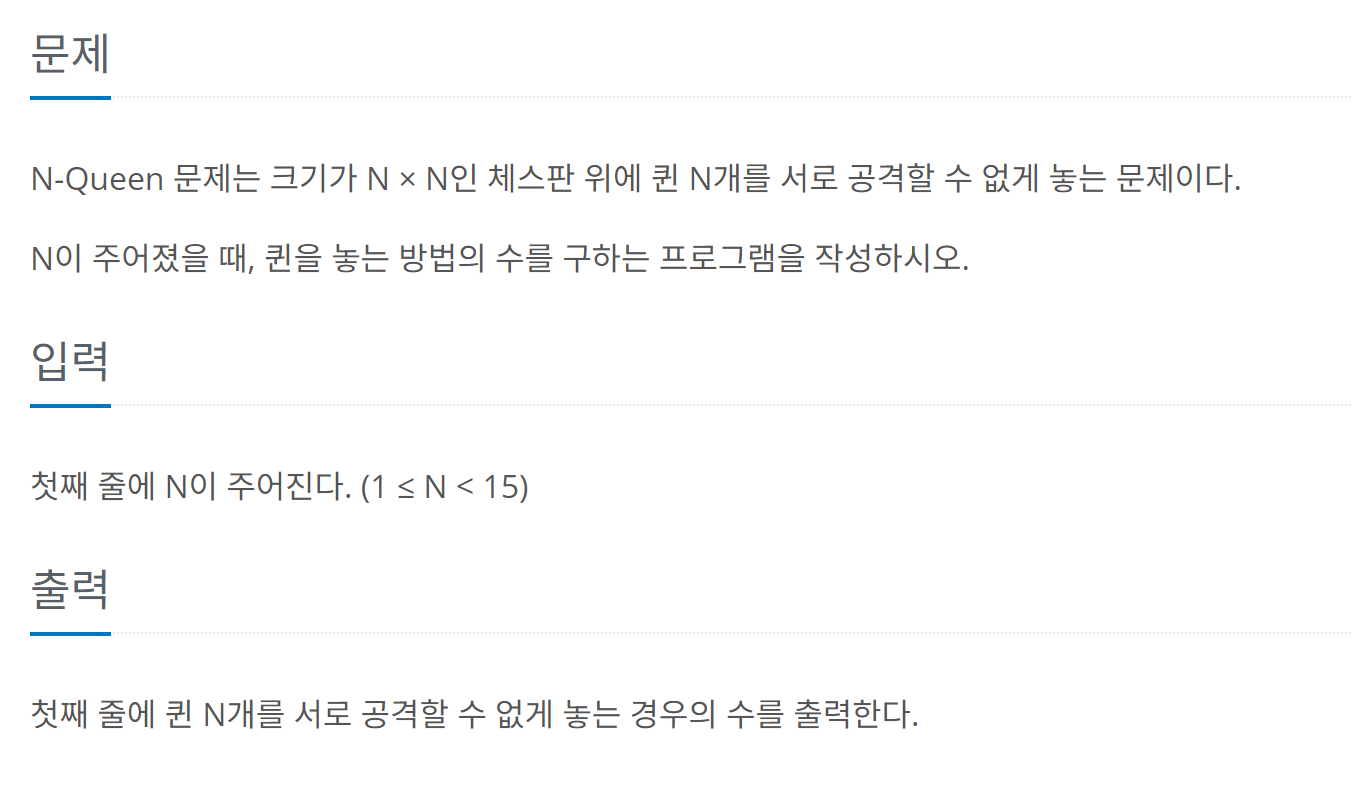
백트래킹이란?백트래킹은 해를 찾는 과정에서 여러 가능성을 탐색하다가, 특정 경로가 잘못되었음을 알게 되면 되돌아가서 다른 경로를 시도하는 문제 해결 기법이다. 모든 가능한 경우의 수를 탐색하지만, 가지치기(pruning)를 통해 비효율적인 경로를 배제하여 효율성을 높인다. 다시 말해, 완전 탐색(브루트 포스)의 개선된 형태라 할 수 있다. 단순히 요약하자면, 백트래킹은 "이 길이 아닌 것 같을 때 원래 왔던 길로 되돌아가서 다른 길을 가보는 것"이다. 이는 특성으로 알 수 있듯이 대부분 DFS로 구현할 수 있다. 백트래킹의 예시이번 예시는 9663번 N-Queen 문제를 기준으로 하겠다. 먼저 구현 문제를 보자. 문제 자체는 백트래킹을 잘 활용해야 풀 수 있다. 나는 문제를 다 읽고 2차원 배열로 풀..