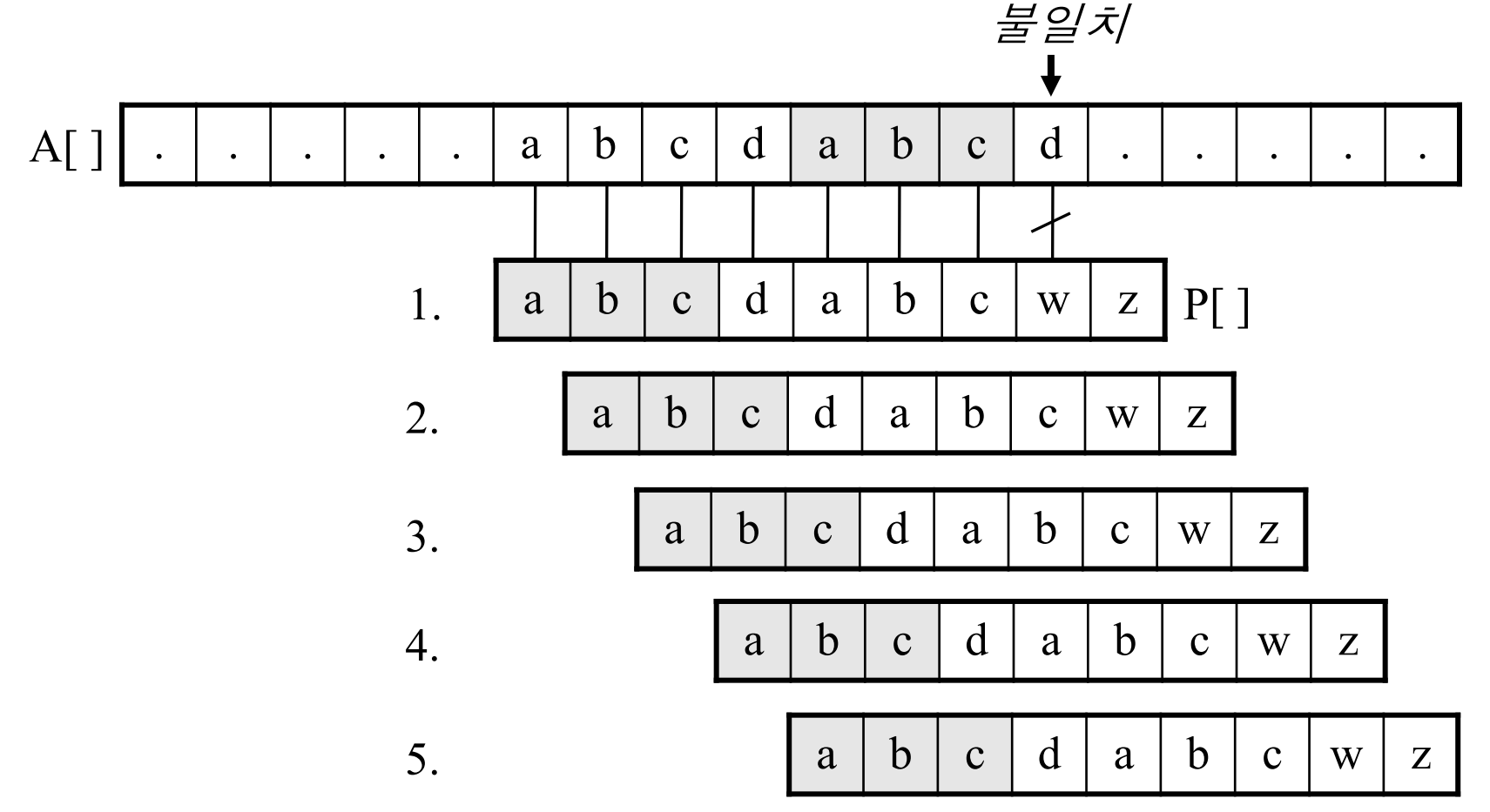
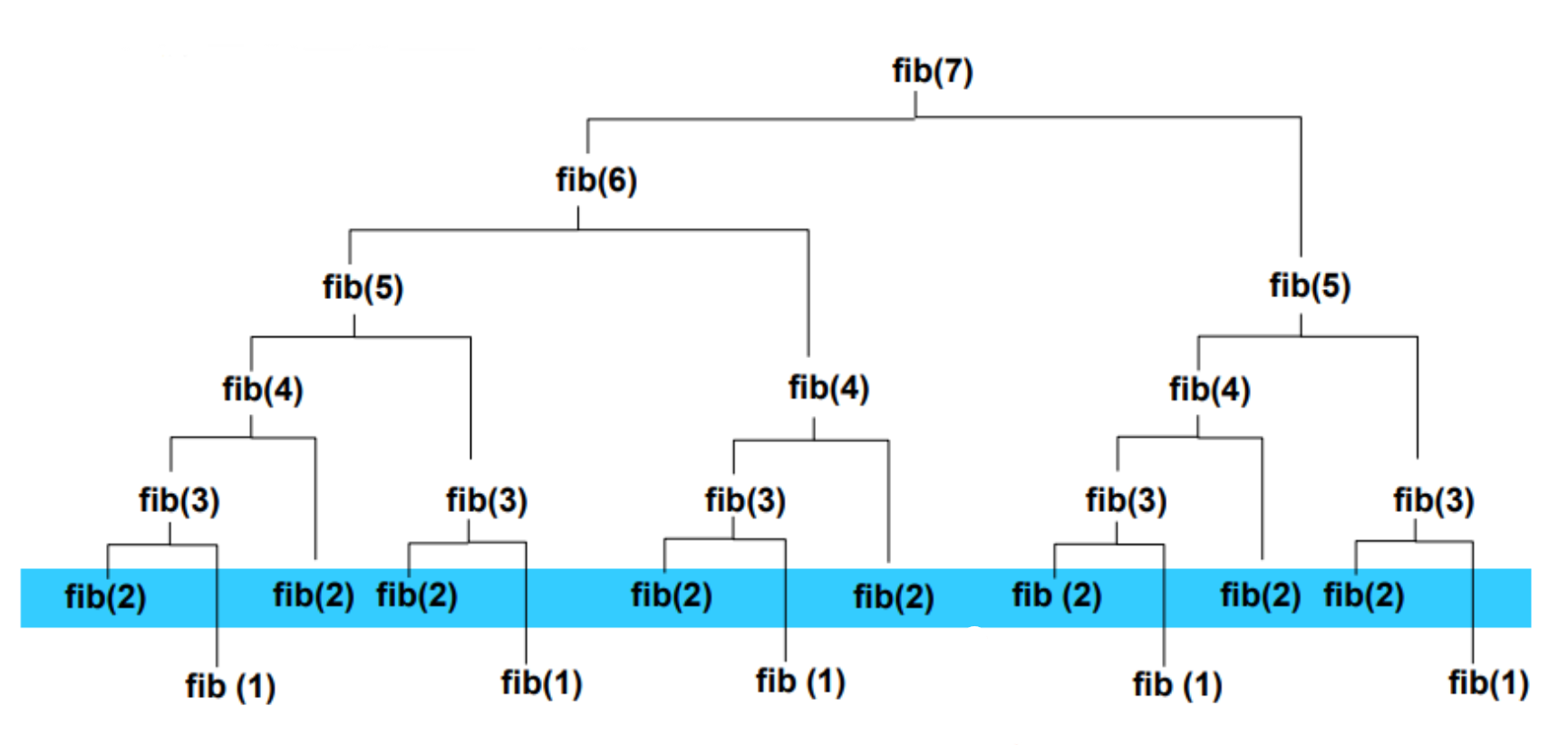
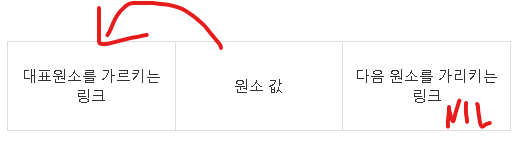
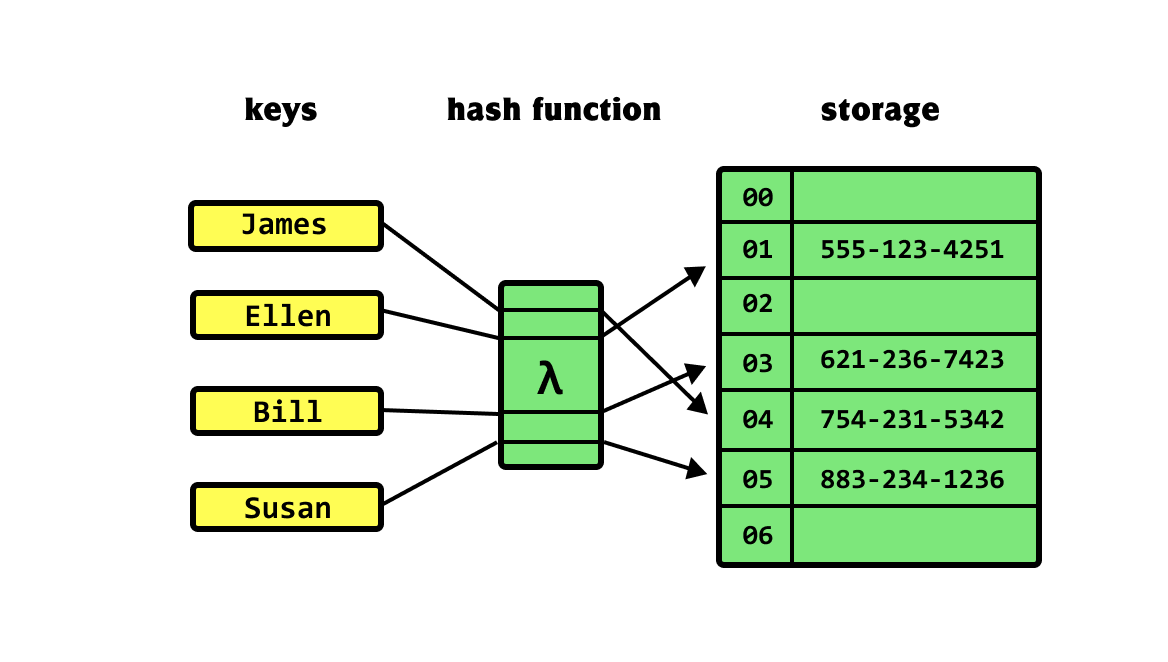
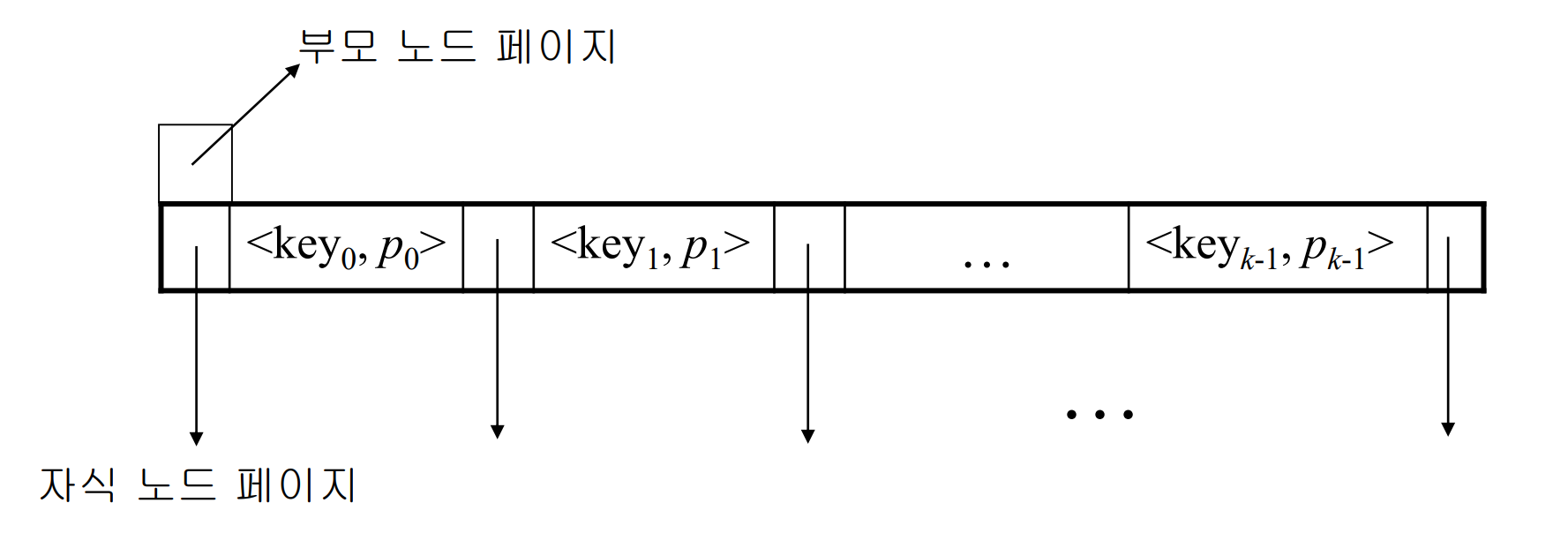
NP 완비 NP-complete 요약하자면, 현실적인 시간 내에 답을 얻을 수 있는 해법이 존재하는 것을 말한다. 여기서 이제까지 다룬 모든 알고리즘은 다항식 시간, 즉 입력 크기가 n일 때 최악의 경우에도 수행시간이 O(n^k)의 시간이 걸리는 알고리즘들이었다. 하지만 모든 문제를 컴퓨터로 다항식 시간에 풀 수 있지 않다. 정확히는 풀 수 있으나 현실적인 시간 내에 풀 수 없는 문제가 있고, 아무리 시간이 주어져도 풀 수 없는 문제가 존재한다. 간혹 들어보는 표현 중에 "슈퍼 컴퓨터로 몇 십년 이상 걸리는 문제"가 그것이다. P 는 polynomial이란 의미로, 문제가 주어졌을 때, 대답을 다항식 시간에 할 수 있는 문제이다. NP는 yes라는 근거만 주어지면 다항식 시간에 풀 수 있는 문제이다. N..