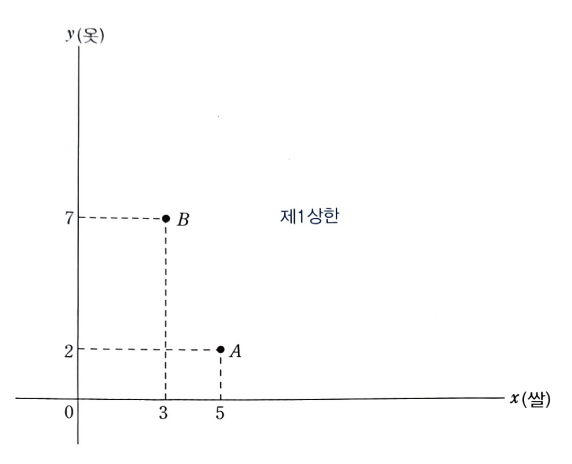
사회복지제도의 분석 소비자 이론을 응용해서 사회복지제도와 관련된 세 가지 지원방식의 차이를 비교해볼 수 있다. 여기서 어느 보조 방식을 쓰든 예산은 한정돼있다고 가정한다. 이렇게 하면 각 보조방식의 차이를 분명히 나타낼 수 있다. 그리고 비교의 편의를 위해서 두 개씩 각각 비교를 한다. 현금보조와 현물보조 현금보조는 말그대로 현금을 지원하는 것이고, 현물보조는 쌀이나 물, 라면과 같이 생활에 필요한 물품을 직접 주는 것이다. 보조를 받기 전인 기존 예산선은 선분 AB다. 여기서 만약 현금보조를 받는다면 예산선은 선분 CD로 이동한다. 그러나, 현물보조를 받는다고 가정하면 꺾인 선 AF'D이다. 이는 선분 BD만큼의 쌀을 공급받는다는 것을 알 수 있다. 이 두 경우의 차이는 꺾인 선 CF'A가 포함되어 있..